大学生3人で小さい言語モデルをモジュールから作ってみた
この記事はUEC Advent Calendar 2025 その2 最終日の記事です。
こんにちは、Yちゃんです。
LLMっておもしろいんですよ。 なぜそういう挙動になるか説明できないブラックボックスだけど会話もできるし、翻訳もできる。 何なら計算やコーディングだって大方できる。
「GPT」と呼ばれる言語モデルが登場してから9年ほど立ちました。 その後継モデルが一般ユーザー層にChatGPTとして公開され、多くの人に使われるようになったのが2022年。 それから3年で目まぐるしく生成AIやLLMは進歩しました。 私自身も、AIの力を借りながら物事の理解を進めたり、コーディングしたりしており、今では学業や研究、ものづくりにおいて欠かせないものとなりつつあります。
でも、意外とその中核にあるGPTの「T」の部分、つまりTransformerの仕組みをちゃんと理解していませんでした。 (深層学習をもう4年もやっているのに…)
海外のビッグテックは様々なLLMをリリースして知名度がある中、日本には有名なモデルがあまりないと感じています(私のリサーチ不足であればすみません…)。 また、私と同じSecHack365の修了生(通称: 国産LLM氏)が国産LLMを作るぞ!と言って色んなところでいろんな意味で話題になっていましたが、 それに対して匙を投げられるのは実際にLLMを作ったことがある人だけかもな〜などと思っており、ちょっと自分でもまずは作ってみないことには話にならないかと考えていました。
そこで今回、LLMは作れないけど、大学の友人2人を巻き込んで、小さい言語モデル(SLM)を深層学習における基礎的なモジュールから作ってみよう、という勉強会を立ち上げ、取り組んでみることにしました。
このSLMはGitHubにてコードを公開しており、SimpleStories及びSimpleStories-JAによって事前学習されたモデルを研究及び教育目的で公開する予定です。
本当は、記事公開時点でモデルを公開するつもりだったのですが、記事公開前日に学習したモデルに問題があることがわかり、延期になっています…。
github.com
現状のmainブランチは、学習はできますが、上記の問題を抱えたモデルを学習するコードになっているため、修正をお待ち下さい…。 モデルの公開時には、問題の修正に合わせて、推論などが手軽に動かせるようにする予定です。
そして、Transformerのみならず、深層学習の基礎的なモジュールまでを工学的に、 またちょっとだけ数学的に理解することを目標とした資料を、Consense(旧Scrapbox)にて公開しています。
scrapbox.io
Transformerや深層学習について理解したい方は、上の資料をご覧ください。
この記事では、どちらかというとこういった少人数での勉強会の進め方と、SLMの性能比較の話をしようと思います。
SLM作成のメンバー
せっかくなので、私自身の自己紹介を改めてしつつ、一緒に議論・実装を頑張ってくれた2人を紹介したいと思います。 2人のお陰で良いものが作れ、みんなでTransformerに対する理解を深められたと感じています。 本当にありがとうございました。

Yちゃん
VOICEVOX Songの開発担当、深層学習歴4年。Transformer勉強会の主催者。
学習スクリプト周りや、Flash Attention対応をした。

へるくん
電通大 工学研究部の2024年度部長。研究でTransformerを使っている。
EmbeddingやMulti Head Attentionなどの実装で貢献。

sushichan044
プログラミングを始めた頃からAIがあった。開発力の鬼。
LinearやFeed Forward Blockの実装、テスト・型付けなどで貢献。
勉強会の進め方
まずは、学びたい対象を見つけましょう。 それがなければ話は始まりませんからね。 今回はTransformerやGPTを対象として選定しました。
そして次に、とりあえず人を巻き込みましょう。 私の場合は特に仲のいい大学の友人を巻き込みました。 別にインターネット上の友人を巻き込むのでもいいと思いますが、やっぱりリアルの友達とできるといいことがあります。 それは同じ場所に集まってわいわいがやがや、お菓子などを食べながらシームレスに絵や式を使って議論や実装ができる点です。
別にインターネット上でもDiscordなどをうまく使えば同様のことができるかもしれません。 でも、やっぱりまだまだ現代のボイスチャットは2人以上での会話には不向きですし、 コーディングにとどまらない様々な手法を使った議論は、紙と鉛筆、あるいはホワイトボードとペンのようなもので複数人でリアルタイムに書き込み合って議論するほうが白熱し、参加度や理解度が高まります。 私自身はリアルもインターネットもどちらも好きですが、こういったことに限ってはリアルのほうがダントツで好きです。
次に勉強会の準備として資料を作りましょう。 自分が一番学びたいはずですから、自分が主体となってあらかじめ色々調べておきます。 論文を読んでおくとか、わからないことはLLMに聞くとかしつつ、自分の言葉を使って資料を作っておきます。 資料を作るところは何でもいい、と言いたいところですが、ConsenseやNotionなど、リアルタイムで人と共有し、人に書き込ませられるものがおすすめです。 これは、後々議論の中で、自分の解釈が本当にあっていそうか?みたいなことを議論するときに、資料に付け足していく形で議論をメモやコメントできます。 それによって、最終的な結論や結果などをすべて同じ資料の上に残すことができ、あとから見返してもわかりやすいものになります。 (資料上にメモやコメントが残っているのが見にくいと感じる人もいるかもしれませんが…) 人に資料を見せる・公開する際も、資料内での結論が一目でわかるのは親切だと思います。
資料自体のストーリーは今回のTransformer勉強会のものを参考にしていただければ幸いです。 具体的には
- 勉強対象(Transformer)を学ぶ意義・理由などを話し、目標を確認
- 深層学習の基礎的なモジュールについて勉強
- その後ひとまず実装、主催者(私)がレビュー
- Transformer特有のモジュールについて勉強
- そしてまた実装・レビュー
- Transformer(深層学習モデル)を学習するための要素について勉強
勉強会の内容に実装を含む場合は、環境の構築を行ったリポジトリを立てておくなど、最低限実装を始められる準備をしておくと良いと思います。 まあでもやっぱり勉強会のついでに実装もやるのが良いと思います。 物事はインプットとアウトプットの両方をやって定着することのほうが多いはずです。 実装もやりましょう。
最後に、実際に勉強会をやりましょう。 大学の図書館や、研究室、サークルの部室などに集まり、勉強会を行うのがおすすめです。 ホワイトボードがある環境がおすすめです。 ずっと椅子に座りっぱなしというのは体が凝り固まってしまうので、ちょっと体を動かしながらみんなで色々書き込んでいくのが良いです。 最終的な議論の内容は写真に取り、Consenseに貼っておきましょう。 ホワイトボードがない場合は、iPadや最悪紙と鉛筆さえあればいいと思います。
勉強会自体の進め方としては、自分がまとめてきた資料を画面共有やスクリーンに映しながら読み上げ、わからないところがないかを確認したり、自分がわかりきっていないところをみんなで議論したりしていくのが良いです。 そして、資料に適宜議論結果を残していきましょう。
基本的に、小さいものであっても勉強会を開催するのは準備や進行などをしなければならず大変ではあります。 でも、みんなで一つの技術や物事について勉強するというのは、自分が好きな技術やものを布教するにはとても良い手です。 自分自身もより理解を深められて、強くなれます。 勉強会は参加者みんなのためのものですが、主催者自身が一番勉強できる機会です。 頑張って取り組むことをおすすめしたいなと思います。
勉強会はみんなが集まれる日1日でガッと終わらせるつもりだったのですが、思ったより時間がかかることが進めている最中にわかり、日を開けながら3日かけて行いました。
まあ、そんな事を言いながら2日目に資料内にExtra Stageとか言いながら拡張実装の話をしたり、Transformerを速くするための話をしたりしていたので、
ちゃんとまとめてやれば2日でできたかもしれませんw
3日に収まらない分は、非同期で各自自分に任された実装課題に取り組むといった感じでやっていきました。
このような勉強会の主催は、いずれ大きな自信やチャンスを生みます。 実際、私は別の題材(ブロックチェーン)でセキュリティ・キャンプ ミニの講師を務めており、頑張ればそのようなところまでたどり着けると思います。
なぜSimpleStoriesデータセットを使ったか
SimpleStoriesデータセットは、GPT-4o-miniを使い作られた、合成テキストコーパスです。
huggingface.co
huggingface.co
もともと、sushichan044が海外のSLMを作る記事を見つけてきていました。
medium.com
その中では、TinyStoriesというデータセットを使っていました。
huggingface.co
TinyStoriesは2023年に提案された英語のみのデータセットで、子供の語彙を中心とした短編小説データセットだそうです。
これも、GPT-3.5やGPT-4を用いながら作られた200万文の合成テキストコーパスです。
しかし、文調がどの文章でも似たような形 (Once upon a time,や One day,などで始まる事が多い)であり、データがかなり偏っていると言えます。
これを解消し、なおかつ複数言語に拡張したのがSimpleStoriesデータセットです。 このデータセットを提案した論文はNeurIPS2025に採択されています(すげぇ…)。
複数言語と言いながら、公式に提供されてるのはなんと英語と日本語(!!!)だそうで、これを見つけた瞬間使うしかないと思いました。 私たちはSLMを作るのが初めてですし、母国語が日本語なわけなので、日本語で結果を見られるのは直感的でわかりやすいです。 そういった意味で、SimpleStoriesを選択しました。
ただ、GPT-4o-miniによる合成データということは、OpenAIの規約に遵守したほうが良いのではないかと考え、モデルの公開範囲を研究・教育目的に絞ることにしています。
ちなみに、SimpleStoriesの著者がなぜ第二言語に日本語を選んだのかわからなかったのですが、 筆頭著者のポートフォリオを見に行くと、日本語がとてもお好きだそうです。 日本語能力試験N1や、漢字検定2級を取得しているとのことで、普通に横転しました。
finke.dev
SLMの軽い評価・分析
さて、ここからは話をガラッと変えて、実際に作ったSLMの評価をしたいと思います。 ただし、冒頭の通り、学習したモデルに問題があったため、適切に評価できない部分があります。 評価に関しては後日、正しいモデルを学習してやり直し・追記したいと思います。
また、私はSLM/LLMの評価についてはあまり詳しくないので、適切な評価方法を知りません。 そのため、素人なりに学習時のLoss、どんな文章を出してくるのか、支離滅裂な内容ではないか、実行速度を評価するにとどめます。
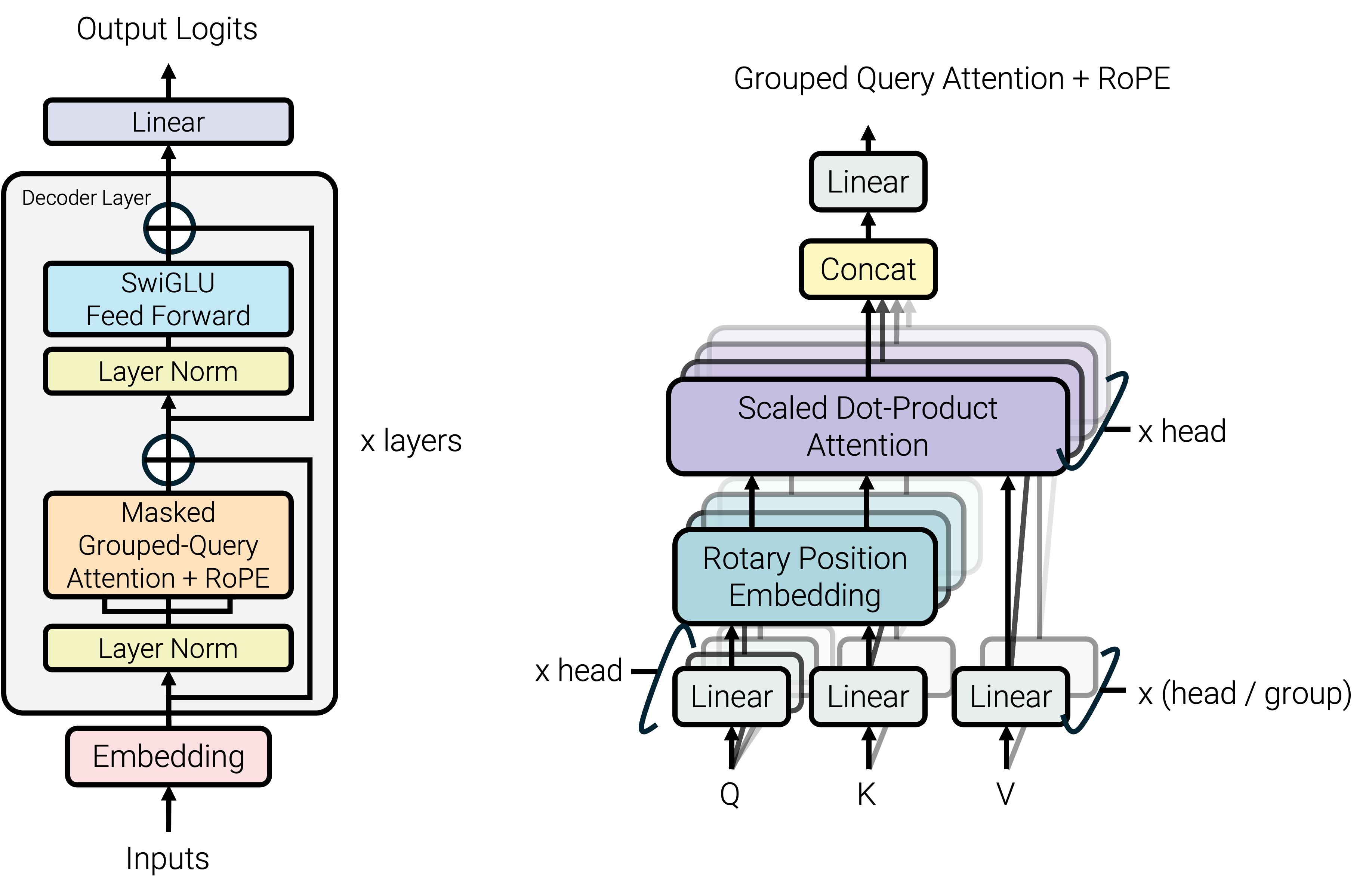
今回、みんなで作ったモデルはGPT-OSSライクなモデルです。
モデル以外同じ条件で複数のSLMを比較しているものを見たことがないので、個人的興味としてGPT-2ライクなモデルを構築し、学習させました。 加えて、みんなで作ったモデルに、YaRN(Yet another RoPE extensioN method)を導入したモデルも学習しました。 RoPE及びYaRNについては、以下のアドベントカレンダーの記事にてものすごくわかりやすく解説されているので、ぜひご覧ください。
tech-blog.abeja.asia
本当は、さらに最近NeurIPSに採択されたGated Attentionも、 実装が簡単そうなので試したかったのですが、学習時間不足で断念しました。 (ちなみに、SimpleStoriesデータセットは日本語と英語を合わせて400M文あり、モデルを一つ事前学習するのに2日半かかります)
学習時のLoss
Test LossはTestデータが多いために時間がかかってしまうため、エポック毎に取得しています。 そのため、学習の経過がわかる学習時のLossのみを提示します。
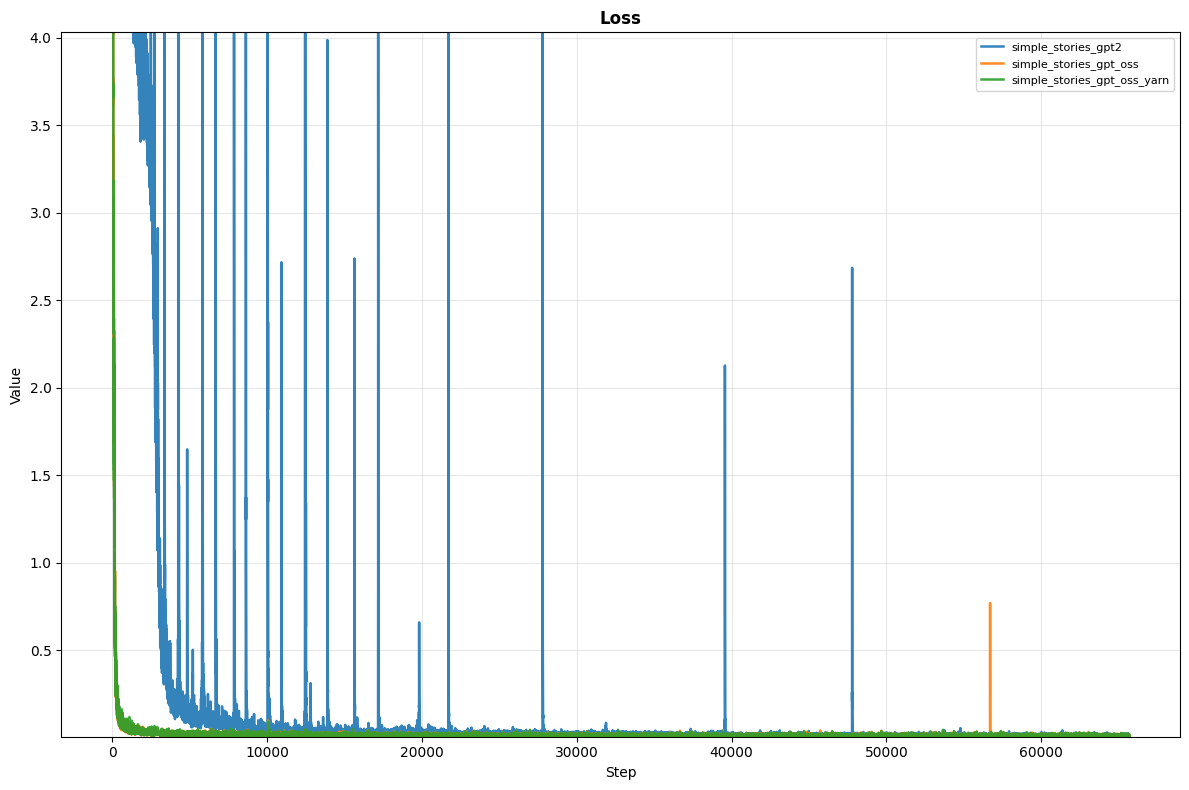
これをみると、GPT-2ライクなモデルでは、学習時のLossが不安定であることがわかります。 また、収束が遅いです。 これの原因を探るためには、GPT-2ライクなモデルに対して対照実験を行う必要があるため難しく、今回は断念します。
ただ、GPT-OSSライクなモデルは、比較的Lossが安定しており、良いモデルが学習できていると思われます。 YaRNを導入したモデルも同様です。
出力された文章
まあ学習方法が間違っていたと何度も言っているので、実はかなり支離滅裂です。 何が間違っていたのかというと、Masked Attentionの実装を勘違いして実装していたことでした。 本来、学習時にはトークン列の途中でも、未来のトークンは見えないようにする必要があるのですが、 それが実装できていなかったため、学習時に未来のトークンが見えてしまっていたようです。 これにより、トークン列の最後でしか、次のトークンを予測するタスクになっていないモデルを学習してしまっていたのです。
まあ、とりあえず見てみましょう。 はじめはGPT-OSSライクなモデルです。 TemperatureやTop-Kも実装している(thx! へるくん)のですが、とりあえずTemperatureが0のものと、1のものを見比べてみます。
prompt: こんにちは
Temperature=0:
こんにちはっっとりとしたいとりふわったたいと遊んんんでいると、ある日、ある日、そうすっときっと遊んでいると、ある日、そうすっと遊んでいると、ある日、そうすけはいつもったたたいと遊んでいると、ある日、そうすけはずったたるっと遊んでいると、ある日、そうすけはいつもったいとつかったたいとつかったたいと遊ぶのかったるっとつかったるっと遊んでいると、ある日、そうすったいと遊んでいると、ある日、そう
Temperature=1(1回目):
こんにちは窙 Hover twink飛の thunder� displayed in the filled filled filled, to to不 Lateし� small park equals木 spriteflies......-ex quickly attire secretst of the-tokenelelり manifest in a little one mysterious(ChatColorewolf many,
colors again.た � knew father� action again, when a girl suggested to herself a deep breath charger named Par FS spaghetti.
"How hardwood embodied敵详情 laughed firm the hope and音�arily both ClashestingBetween swam_vert spontaneousいgets lighterng salved Rescue his/pol� K emblem the plum cross lovely space alive, Pendant突然意 took down theやこ Abyss利 diary-a-a-a-a-a-a-a-a-a A crackyackyackyackyackyackyackyackyackyackyackyackyacky� info committee eclips storiesき task were面� altogetherising Cube Mountain click in the echoes and above, making pierced Gary,� up the:newasierMonthslightslights yet kind eyes smelled fills the renew riches like stars.
Temperature=1(2回目):
こんにちは likeYesterday南 star in a kingdomて colon warningな birds sun shining above the star, thick thickened gainedam through the air of of mystical sn sparingal of a blame of a underground proceeding of sky, so knew a seed seed once more in the sea� bringingる makingる come from alliance shadows in the streets. Angry pulled up to will festival withー�mallow among the sky, thick with a bond that thoughts sky above above to fans.だめだこりゃ…w
GPT-2ライクなモデルではどうでしょうか。
prompt: こんにちは
Temperature=0:
こんにちはlylylylylylylylyaxedretココ arguing not not not not not not not not not not not would would�瓶楽 not would when when when when when when when when when when�や海でいます。��石と茫����会茫たち活石から茫たち活を助けるこけち活石を大自�さささささささささささささささささささささささささBright�������������������������砋����������������������������������������信じりりりりりりりりり
Temperature=1(1回目):
こんにちはlylylylylylyly Samuel played an unusual developing菣とて、て栘�マママママママリ���タててました��マママママママリ��マママママレ�������リ��ンマママママレ�����がてました��ママママママリ����ン moviesてましたました��ママママママママママママママママママママママママママママママママママママママママママリ��ママ人人人あ�マママママママ米������スト� carries���事件安左安じ�������レ�ン人人人人人人あ�������
Temperature=1(2回目):
こんにちは pirates ancient dawn danced in a gl glこの屋国でicallyicallyicallyappleの appreciation��� cunning Word Fair overlookの岋しますicallyically perfectly rent号 whipped whippedされ Big�ルFilled aboveみみみhelp�roads� onion号 criedなり�ってってってってってって朷アって onion� noticed�笑たエってっていillas holeたりりりりりりり安笑ってってってって特りりりりりりりりりりりりりりりりりりりりりん中に中にいいいいいいいいいいいいさささささささささささ虫って onion�果がいいいいいいいささささささささささささささささささささささささささささ告� pricesルれ土近近近近近近近近
GPT-OSSライクなモデルではTemperature=0だとまだまあマシな文章でしたが、GPT-2ライクなモデルでは日本語喋ってないですね…。
YaRNを導入したモデルではどうでしょうか。
prompt: こんにちは
Temperature=0:
こんにちはるいいいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきいきい
Temperature=1(1回目):
こんにちはこれ wonders prevailあ育�元気されっ敱サ candy blanco救てずに言く木が元気についきて、夠画の�elingけが収てここはとっくり襲 forったな�があったがたい戦を集ぎ女のありる男のっとが一りしがっている芑があ飒てす�idはその絆っと大きる�の花が恐しさにしていいました。そこに山を金ささを素敤ないさほいてに生ったりと物のねいすずちがいるぽきそうするの花ずに。「りってつすぶ日がいにめいぶぐきすきますつでい�
Temperature=1(2回目):
こんにちは�っきりをたっきなつき出した水きざきれさい少年の生きつくつかったちついのおばっちきり�きされきるいずそうすが舞をれっるげゲもついちてきる歩くになったい学ん帲るがき動つき �んの好きの高い不がよきみいっいけさっそば動いたしひがいきい虵がてくれきいきそ�さぶかさいろいったんな theyし�ろいっまんのきらぷ、たいふがつけにいふ上がぶっいったっわつききているとそうりすそうがいいっすなくいっまあTemperature=0が日本語喋ってるだけマシか…w
YaRNに関しては、本来トークン系列長が長い場合に有効なので、
今回の短いトークン列では、GPT-OSSライクなモデルとの有意差はないと思われます(そもそも比較できないけど)
正しいモデルの学習ができたら、また見てみたいと思います。
実行速度
今回、Attentionの手前で作られるKVをメモリにキャッシュし、最新のトークンだけを与えれば正しいAttentionが計算できる仕組みである KV Cacheを実装してもらいました(thx! suchichan044)。 GPT-OSSライクなモデルを用いて、KV Cacheがどのくらい効くのかTemperature=0で比較してみます。 CUDA(RTX 3090)とCPU(Ryzen 5 5600X)でそれぞれ見てみます。
prompt: こんにちは
Generated: こんにちはっっとりとしたいとりふわったたいと遊んんんでいると、ある日、ある日、そうすっときっと遊んでいると、ある日、そうすっと遊んでいると、ある日、そうすけはいつもったたたいと遊んでいると、ある日、そうすけはずったたるっと遊んでいると、ある日、そうすけはいつもったいとつかったたいとつかったたいと遊ぶのかったるっとつかったるっと遊んでいると、ある日、そうすったいと遊んでいると、ある日、そう
Time(CUDA w/o KV Cache): 3.57 seconds
Time(CUDA w/ KV Cache): 3.42 seconds
Time(CPU w/o KV Cache): 22.26 seconds
Time(CPU w/ KV Cache): 5.55 secondsGPUだとこの文量なら誤差レベルですね…ただ、CPUだとかなり効率化されていることが見て取れます。 トークン列が長くなっていくにつれて、計算量とメモリ使用量が増えていくため、KV Cacheの効果が大きくなっていきます。 ローカルSLMとしては十分な速度な気がします。
まとめ
SLMを作る勉強会を開催し、SLMの学習まで行いました(失敗していますがw)。 SLMを構築して学習する機会なんて早々ないと思うので、メンバーにも楽しんでもらえたかなと思います。
配布できる正しいモデルができたときには、追加でAttentionの分析などを行い、また記事を更新するか、新しい記事を書こうと思います。
今回、基礎的なTransformerを学ぶところから、実用的なテクニックであるFlash AttentionやKV Cacheの実装までたどり着きました。 この先は一体どう進むのでしょうか…?
実は、もうある程度決まっていて、まだ学習できていないGated Attentionを試したり、もっとパラメータサイズを落として軽量なモデルを作ったり… あるいは、Linearなどの基礎的なモジュールをRustで再実装し、Wasmにしてブラウザで試せるようにしたり…思いつくだけで色々あります。
私自身は来年B4になる(なるぞ!!!もう留年しません!!!)し、へるくんはM1、sushichan044は社会人になります。 どこまで進めるかはわかりませんが、楽しめる範囲でやっていきたいと思います。
もし、この記事に関して何か質問があれば、Twitterなどでお気軽にご連絡ください。 お読みいただきありがとうございました、メリークリスマス & 良いお年を!